
Why Human Validation Still Matters in AI-Powered Product Data Enrichment?
Many eCommerce teams have already handed product data enrichment to AI, and for good reason, as it fills catalogs faster than any manual process can.
The question is no longer whether to automate, but how much of the process to leave entirely to it.
AI-powered product data enrichment populates product attributes at scale, which makes individual errors easy to miss. As a result, inaccurate attributes can reach on-site search, product feeds, and live listings before they are caught.
For a large-volume catalog, accuracy matters more than speed. Human validation is essential to ensure AI-driven enrichment improves catalog quality without introducing unreliable data.
Where Automated Enrichment Gets Product Data Wrong
AI product data enrichment tools can populate incomplete product records at a scale and speed no manual team can match. The efficiency is real, but so are the limitations of AI in data enrichment, which often surface only after the listings go live on the storefront.
Three failure points account for most of the damage.
Fabricated Specification Data
This occurs when source information is missing, and the AI fills the field with a self-generated value instead of leaving it blank. Because the value appears appropriate for the category, it can look accurate even when it is not.
For instance, a wireless earbud listing with missing battery-life details might be enriched with “up to 8 hours of playback” simply because that figure is common for the product type, even though the actual model may last only 5 hours. Nothing in the source supported the number; it was generated to complete the field.
Faulty Attribute Inference
The AI product data enrichment tools take an attribute value that is accurate for the broader category or for a closely related product. Then, it applies it to a specific variant where that value is incorrect.
For example, in a television series where most models are 4K, the model may assign “4K resolution” to a 1080p variant in the same line, leaving attribute coverage technically complete but factually wrong. The data exists; it has simply been mapped to the wrong product.
Category And Taxonomy Misclassification
Category or taxonomy misclassification occurs when a product is placed in the wrong category, even if that category seems related to the product.
For example, a portable SSD may be classified as a USB flash drive because both products have a similar form factor and may share similar search terms. However, they are different product types with different attributes, filters, and comparison criteria.
This type of error can be harder to identify than an incorrect specification because the product record may still look complete. The issue becomes visible in catalog navigation: the product appears under the wrong filters, is grouped with the wrong products for comparison, and becomes harder for customers to find through faceted search.
Why Inaccurate Product Data Enrichment Costs More Than Slow Enrichment?
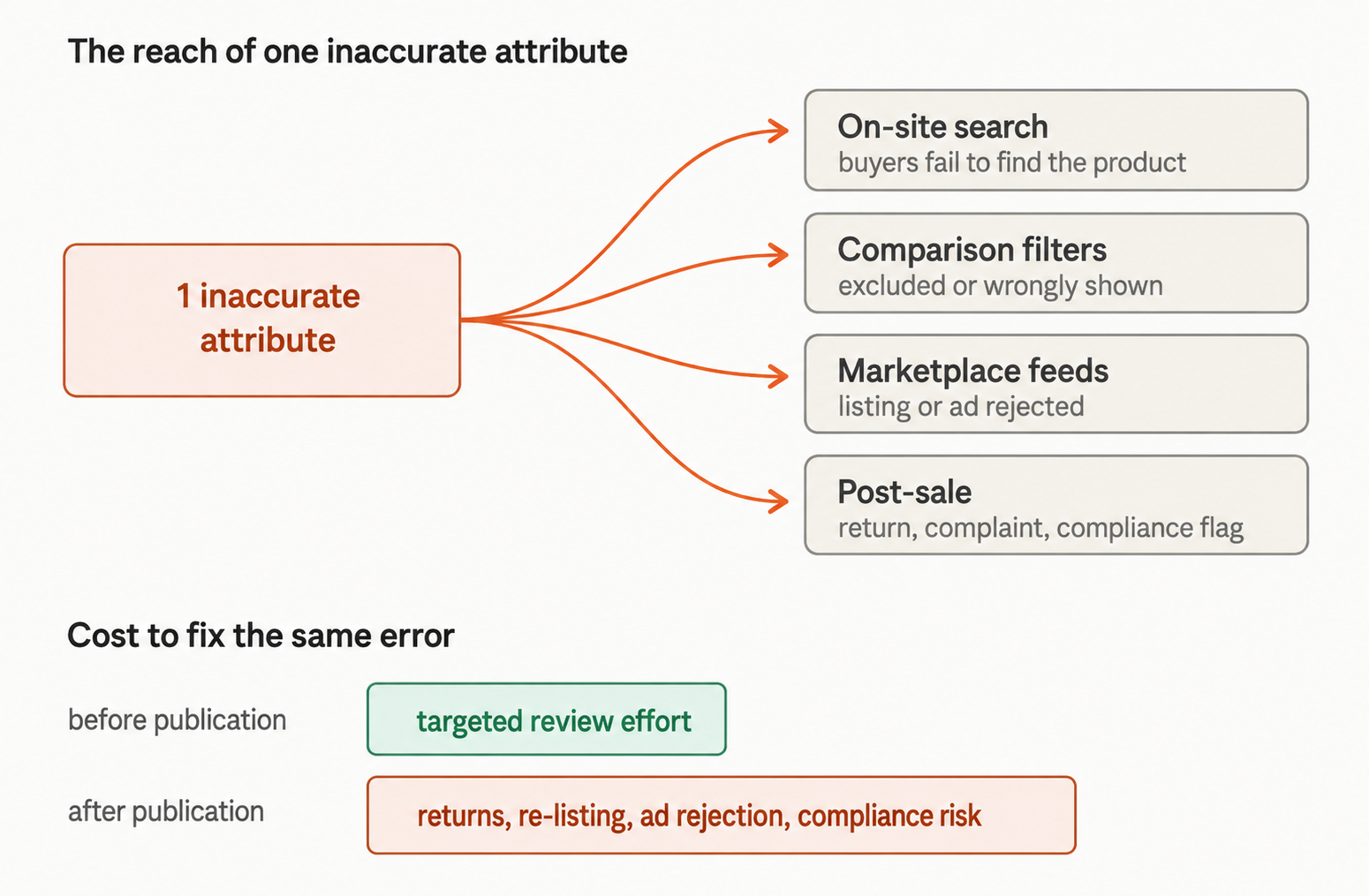
The appeal of AI product data enrichment is the time it saves, but speed loses its value when the enriched data is wrong.
An inaccurate attribute does not stay contained to the field it occupies. The same value is carried into on-site search, comparison filters, and the feeds that push listings to marketplaces, where one wrong specification can lead to a return, a customer complaint, or a suppressed listing.
The expense is rarely visible at the point of enrichment.
A faster catalog launch improves time-to-market, but if the underlying product data quality is weak, that gain is offset later by returns processing, re-listing work, and ad disapprovals on platforms that reject mismatched data.
In categories governed by regulation or strict platform policy, such as supplements, cosmetics, and electronics with safety certifications, the risk goes beyond cost. An incorrect ingredient, voltage rating, or age grade can breach marketplace rules or local law.
To sum it up, ensuring data quality in AI workflows is therefore less about slowing the product data enrichment process; it is about paying a small review cost upfront instead of a much larger one after publication.
What Human Validation Adds, and Where It Belongs in the Workflow?
AI handles product data enrichment, including generating attributes, filling gaps, and formatting values at a scale that manual teams cannot match. What it cannot do is confirm if those values are correct.
That judgment is the role of human validation, and knowing where to apply it is what keeps AI product data enrichment both fast and accurate.
What Automated Enrichment Cannot Confirm?
A record can seem complete and correctly formatted and still contain values that are wrong for the specific product. AI cannot detect that gap on its own, which is where human validation in AI becomes necessary.
| Tasks AI Can Perform | Human Validation Confirms |
|---|---|
| Populate the field | The value is factually correct |
| Apply a valid format | The value matches the variant, not just the category |
| Fill every missing attribute | The right attribute is chosen in ambiguous cases |
| Keep values internally consistent | Brand and regional regulatory rules are met |
| Assign a taxonomy value | Cases with no precedents are judged correctly |
Reviewers verify product data against trusted sources, such as manufacturer specification sheets and official brand or supplier documentation, rather than relying only on the model’s predicted pattern.
Applying Validation Selectively to Protect Speed
A frequent concern is that introducing manual review reduces the efficiency that automation delivers. A well-designed human-in-the-loop product data enrichment process resolves this by directing review to where it matters most rather than across every record:
- Confidence-Based Routing: When the enrichment model attaches a confidence score to each value, those above a set threshold publish directly, while low-confidence values are routed to a reviewer.
- Risk-Based Sampling: Reviewers prioritize the categories and attributes where an error is most costly, such as safety specifications and compliance fields, rather than checking every field equally.
- Manual Checkpoints: Enriched data is reviewed at set points in the pipeline before it reaches search, product feeds, and live listings.
- Feedback Loop: Corrections are fed back into the prompts and rules that guide the model, ensuring the same errors recur less often over time.
Applied this way, validation becomes a designed stage of the eCommerce product data enrichment workflow instead of an afterthought. The aim is not to review every record but to direct human attention to where the risk is highest, letting automation carry the volume while human judgment secures the accuracy that volume depends on.
Building Validation into AI-Powered Product Data Enrichment
Validation is most effective when it is part of the enrichment process from the start, not added once listings begin to underperform.
In practice, that means setting clear accuracy thresholds, maintaining audit trails that record what was changed and why, and assigning clear accountability for what enters the catalog. Checking data before publication prevents errors from reaching customers; correcting it afterward only addresses the cost once it has already been incurred.
As AI expands enrichment at scale, output quality hinges not on the model itself, but on the validation processes that govern it.
Applied as a standard step rather than an afterthought, human validation is what lets AI product data enrichment scale while protecting product data quality, customer trust, and regulatory compliance alike.
 Author Bio: Ravi Kant is the Vice President of the eCommerce and Photo Editing Division at SunTec India. With over two decades of global experience, he spearheads large-scale digital commerce initiatives that drive operational excellence and measurable ROI for global businesses. His expertise spans eCommerce strategy, digital transformation, and data-driven performance optimization. He regularly shares insights on product data management, search-led catalog optimization, and marketplace content strategy, enabling brands to strengthen their digital commerce presence, improve operational agility, and unlock scalable revenue growth.
Author Bio: Ravi Kant is the Vice President of the eCommerce and Photo Editing Division at SunTec India. With over two decades of global experience, he spearheads large-scale digital commerce initiatives that drive operational excellence and measurable ROI for global businesses. His expertise spans eCommerce strategy, digital transformation, and data-driven performance optimization. He regularly shares insights on product data management, search-led catalog optimization, and marketplace content strategy, enabling brands to strengthen their digital commerce presence, improve operational agility, and unlock scalable revenue growth.
LinkedIn Profile – https://www.linkedin.com/in/contactravikant/




